교육 받은 내용이 있어 자세하게 설명할 수는 없지만 이번주(9월 2주차)부터 본격적으로 MariaDB와 ElasticDB를 이용해서 작업을 하고 있다. 익숙한 RDB와 나에게 아직 생소한 ElasticSearch를 CS 관점에서 비교해보고자 작성하게 되었다. Elastic Kibana를 통해 편하게 쿼리를 날리고 확인하고 있는데 아무래도 튜플 상으로 데이터를 저장하는 형태가 아니고, ElasticDB를 이용해 실제 SpringBoot와 연동하여 데이터를 저장하는 작업이 난생 처음이어서 앞으로의 작업에 더 박차를 가하기 위해 보충 공부를 하고자 한다. 그래도 처음 ElasticSearch 다뤄본건데 이번 주차에 벌써 API 개발을 진행 중이다~
(사실 이 깃헙 레포에서 ES를 다뤄보고 싶어서 시도만 했었고 db 연동까지는 못한 극 초반의 상태로 방치되고 있었다... 계획만 세우고 실천하지 않은 점을 반성하며 추석 연휴 동안 공부해야겠다)
검색엔진의 표본이라고 할 수 있는 이유
모든 데이터를 JSON 형태의 document 형식으로 관리가 되고 있고 RDB, NoSQL과는 비교도 안될만큼 빠른 속도로 데이터 조회가 가능하기 때문에 복잡한 검색이 효율적으로 가능하다는 점에서 엘라스틱서치는 큰 장점이 있다.
본격적으로 이 게시글에서 Elastic을 살펴보기에 앞서 특정 용어에 대해서 익숙해질 필요가 있었다.
역인덱스 : 엘라스틱 서치의 분석기를 통한 역인덱싱
역인덱스란 책장 맨 뒤쪽에 단어 단위로 나눠져서 어떤 페이지에 나와있는지 적혀있는 것이라 생각하면 쉽다. 엘라스틱서치에 인덱싱을 적용하는 경우 역인덱스 사전이 구축되어 Hash의 조회 시간 복잡도가 O(1)로 매우 빠르듯이 엘라스틱서치의 분석기를 통해 빠른 속도의 검색이 가능하게 된다.
그렇다면 역인덱스를 가능하게 하는 분석기라는 것은 도대체 뭘까
분석기
Elastic에 들어오는 문자열은 분석기를 거쳐 인덱스로 저장이 된다.
엘라스틱서치 분석기는 캐릭터 필터 → 토크나이저 → 토큰 필터 이렇게 세 가지 단계로 구성된다. 각 특징을 살펴보기에 앞서 엘라스틱서치 관점에서 "토큰"과 "용어"의 의미를 구별해야할 필요성이 있었다.
- 토큰 : 문자열이 토크나이저를 통해서 잘리게 되는데 이때 공백 단위로 잘린 단위를 말한다
- 용어 : 토큰 필터를 통해서 최종적으로 정제가 되어 인덱스에 저장되는 토큰을 말한다
문자열을 잘라 인덱스하는 것이 역인덱스 == 역색인이다.
이제 분석기의 각 과정의 특징을 정리하고자 한다.
1. 캐릭터 필터
- 입력받은 문자열 전처리?(내가 이해한 방식으로는 전처리라는 표현이 더 직관적으로 나타낼 수 있을 것 같다)
2. 토크나이저
- 문자열을 토큰으로 분리 → split(" ")
3. 토큰 필터
- 토큰 정교화(대소문자 변경, 형태소 분석 등)
분석기 내부에 토크나이저가 있고 분석기, 캐릭터 필터, 토크나이저, 토큰 필터의 종류가 정말 다양했다. 여러 조합으로 분석기를 구성할 수 있겠구나라는 생각이 들었다.
즉, ElasticSearch의 인덱싱 과정을 정리하면 아래와 같다.
문서가 ElasticSearch에 제출되면 그 문서는 JSON 형식으로 변환되어 인덱스에 저장되고 각 문서는 고유한 ID로 식별된다. ElasticSearch는 문서의 내용을 분석하여 역색인을 생성하며 역색인은 검색 시 문서를 빠르게 찾는데 사용된다.
NoSQL DB로도 사용되는 ElasticDB
엘라스틱은 모든 데이터를 JSON @Document 형식으로 관리하고 Rest API 형식으로 되어있어 NoSQL DB로도 사용이 가능하다.
또한 JSON 형태로 저장된다는 이점을 이용해서 ElasticSearch의 queryDSL을 적용하여 JSON 형식으로 쿼리를 정의할 수도 있다. 필드 타입이 텍스트, 숫자, 날짜 등 여러 유형의 데이터 형식에 대해서 검색 쿼리를 정확하고 빠르게 할 수 있도록 지원한다. 기본적인 검색뿐만 아니라 boolean 연산, 필터링, 집계 등 복잡한 연산도 지원한다.
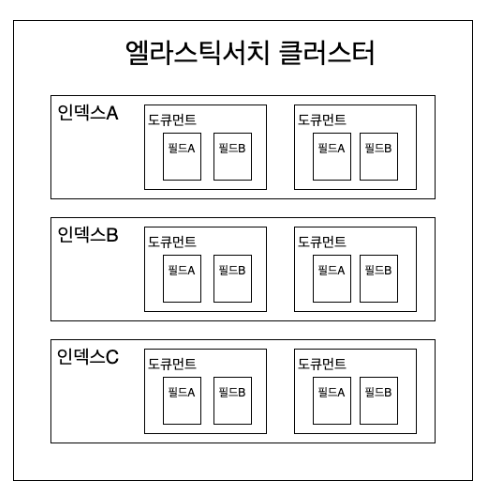
그리고 MySQL, MariaDB와 springboot를 연동할 땐 @Entity 등의 어노테이션을 선언했지만 Elastic을 이용하는 domain의 경우 @Document와 index를 이용했는데 비교해보면 아래와 같다.
| MySQL | ElasticSearch |
| 데이터베이스 | 클러스터 |
| 테이블 | 인덱스 |
| 레코드 | 다큐먼트 |
| 칼럼 | 필드 |
| 스키마 | 매핑 |
그럼에도 불구하고 엘라스틱서치의 단점
1. 엘라스틱은 조인을 허용하지 않아서 concat 등을 사용하여 비정규화를 해야 한다 → Epsormalization 이용히면 조인 연산 없이 빠른 검색과 집계 가능
2. 데이터 insert 시 실시간이 아니기 때문에 딜레이 시간이 필요하다.
(실제로 이번주에 내가 작업한게 insert와 get이 있는데 get은 정말 rdb와 비교할 수 없을 정도로 빠른데 비해 insert POST 요청의 경우 약간 느린 감이 있었다.)
3. 데이터 수정 시 기존의 도큐먼트를 삭제하고 변경된 것을 생성하는 로직이기 때문에 실시간 업데이트 방식이 아니다.
4. 트랜잭션 / 롤백에 불가하기 때문에 메인 DB로 사용되는 것은 위험 부담이 있다.
훑어보는 정도로 엘라스틱서치를 살펴보았는데 추석 연휴 이후 보다 잘 작업하기 위해서 위 레포에서 예제 상황을 만들어서 내가 구현해야 하는 것에 대해 미리 공부를 해야겠다...!!
'CS > DB' 카테고리의 다른 글
| [DB] PostgreSQL pgvector Extension (0) | 2025.04.03 |
|---|---|
| [ERD] 채팅 기능 ERD 설계 고민 (0) | 2024.08.02 |
| [DB] SpringBoot + Redis 활용 방법 (0) | 2024.07.31 |
| [DB] MySQL이 아니라 redis에 refresh token을 저장했을 때의 이점이 뭘까 (0) | 2024.05.09 |
| [DB] index (0) | 2024.04.26 |



